AI Governance Issues
AI will fundamentally change our economy and society—in time. Meanwhile, few orgs are adequately planning for it. Governance and oversight might be a good place to start.

It’s a whole new world with emergent risks and opportunities
AI will fundamentally change our economy and society. But that doesn’t mean it’s immune to hype. The truth is that AI will hit harder than most people expect—but it will take longer to do so. A lot of the capital being deployed towards AI right now will be wasted.
And yet, organizations that aren’t proactively planning for AI disruption may not survive it. The best organizations will: understand AI; have a cohesive vision, strategy, and doctrine for it; and will have suitable infrastructure to adapt as we all learn more precisely how AI will evolve.
Success in the era of AI requires a(n):
- Understanding of AI
- Cohesive AI vision, strategy, and doctrine
- Adaptable AI & data infrastructure
Based on the many conversations I’m having, some of the least prepared people in organizations are also the most senior, including board members. And that’s a significant risk given the substantial implications for governance and strategy that arise in the context of AI disruption.
This article explores some of the broader governance issues facing leadership teams and boards in this new Era of AI. But first, the disclaimer: This is not legal advice. I have a law degree, but I have never taken the Bar Exam, and I’m not qualified to offer anyone legal advice.
Still, given that I operate at the nexus of venture, disruptive technology, and the law, I hope it’s useful for me to describe some of the governance and legal issues I’m thinking about in a world where artificial intelligence is increasingly real and prevalent. It’s wild. And there are tremendous risks and opportunities that few appear to be fully aware of.
I have already written about the pace of advancement in AI, and its often surprising capabilities. AI can create novel ideas, images, and more. It can distill meaning from vast data sets, and propose useful plans of action based upon it. The models used to perform these actions are being built on a combination of public and private data, and some that’s in between. It’s likely that your personal and corporate data is implicated, and you may not even be aware of it. In a recent survey, 43% of employees admitted to using ChatGPT, and 68% of those hid that use from their employers.
AI will be used to make decisions, filter information, and answer important questions in your organization. It probably already is being used that way.
Issues
The following issues are framed as questions that you should be asking yourself, your team, and your advisors. Unfortunately, it’s probably insufficient to ask your attorneys, given the novelty and technical complexity of some of these issues. I’ve been underwhelmed with the depth and breadth of understanding out there even among brilliant attorneys I know. The truth is that these are novel issues involving novel technology and probably merit a multidisciplinary team approach.
And they’re posed as questions, because there are no definitive answers on any of this, and the facts make each company’s situation unique. In other words, this is issue spotting, and it’s just the beginning.
Is your data being used for training?
Your corporate data may have been and may continue to be used for training of third party LLMs. This may occur in several ways, including public web scraping, parsing of private data repositories, (in)voluntary sharing by your employees, and even dark web distribution.
For example, when your employees use certain AI models, the data and feedback involved may be used for training purposes. This is exacerbated by the availability of plugins (e.g., for OpenAI) that may share data with third parties. Or it could be as simple as your employees assembling and storing data for use in an AI, but failing to sufficiently protect it.
Originally, OpenAI used customer data for training by default, and only reconsidered after a wave of customer complaints.1 And training use can derive from unexpected sources, such as when questions arose around Zoom’s use of customer data without an option to opt-out.2
The fact is that there are many potential ways in which your organizational data may be at risk of being used for training.
- Could this result in trade secret or other intellectual property risks?
- Could it provide useful intelligence for your competitors?
- Could it form the basis for new competitive entry, for example a new product or startup that might seek to replace your existing offering(s)?
- Does your organization have downstream liability for use of that information (e.g., privacy violations, confidentiality violations, public disclosure violations)?
- How should you respond to an LLM (accidentally?) training on your data leaked through a data breach?
Are you using LLMs or data improperly? Consumer privacy?
It’s likely that some of your employees are utilizing AI models without your knowledge. If so, there’s a risk that your employees are unintentionally (or perhaps intentionally) violating licensing agreements for the model and / or for the content they’re feeding it. Even authorized use by your employees risks improper use.
It’s possible that any training, embedding, or use of your corporate content could violate existing legal agreements with your vendors or partners, or violate the many regulations that govern the use of personal information (HIPAA, GDPR, etc.).
For example, your employees might be using information licensed from third parties for training, RAG (Retrieval Augmented Generation), or otherwise in ways that expose it to reuse by those third parties or in ways that violate their licensing agreements.
Consumer privacy is another area of significant risk. “Data Intelligence” requires making your data broadly accessible and usable. Unfortunately, that may conflict directly with certain aspects of consumer privacy regulation. And privacy is very different in the world of AI, which can increasingly reconstitute anonymized information in ways that seem miraculous.
What happens if the AI system infringes on someone else's intellectual property rights in the course of performing its tasks? Who is liable in such a situation—the employee, the employer, the developer of the AI system, or all of the above?
- How are you planning to navigate the conflict between being ready for AI (Data Intelligence) and consumer privacy regulations?
- Have you considered privacy requirements and risks associated with the use or training of LLMs?
- Have you considered licensing requirements and distribution / reuse risks associated with the use or training of LLMs?
- Have you assessed the risks associated with your AI models accessing / using third-party or protected content?
What are the security risks associated with using AI?
Advances in AI systems have created novel security risks. Suddenly, disparate information that would otherwise be mundane might be used by adversarial AIs to derive unanticipated insights and details about your organization (similar to the privacy risks mentioned previously). That’s particularly risky in the context of public companies, who may be inadvertently sharing confidential information.
And then there’s the emerging risk of data breaches driven by adversarial AIs, or even through inadvertent disclosure through your own AI systems. It’s likely that your internal AIs will be fed an increasingly broad set of your corporate data, leading to significant risks of disclosure that may be difficult to foresee or mitigate.
- Have you assessed what data is being utilized by your AI systems, and what risks that might pose?
- Have you assessed the risks of unanticipated disclosures based on the assembly of what might otherwise be innocuous corporate data?
Do your AI models perpetuate bias or discrimination?
It’s likely that some of your employees are, or soon will, train LLMs either from the bottom up, or by embedding content on top of an existing model. But that introduces myriad risks, including significant risks of bias and discrimination. Even if you’re using entirely third-party AI systems, you may face risks based on the outputs you create with them, or any decisions you make using them.
Large Language Models are like mirrors held up to society—they reflect back what they see. We have already seen how insufficient guard rails can result in catastrophic results—for example, Microsoft’s Tay chatbot that learned from users and quickly devolved into racist rants.3 Bloomberg research found that GPT 3.5 systematically ranked job candidates with names that appeared Black or Hispanic (with otherwise identical resumes) lower than those with White or Asian sounding names.4
Even the most carefully curated datasets can reproduce racial, gender, and other biases, which could lead to liability for your organization. As seen in the Bloomberg research example, using AI in the recruitment process could easily lead to significant risk. Or applying generative AI models to the loan qualification process could violate federal discrimination law—perhaps simply by lacking explainability, even absent evidence of bias.
More recently, something went awry in the training of Google’s Gemini AI. As reported in the New York Times,5 if you ask Gemini to generate “an image of a 1943 German Soldier,” the images are, to say the least, inappropriate.
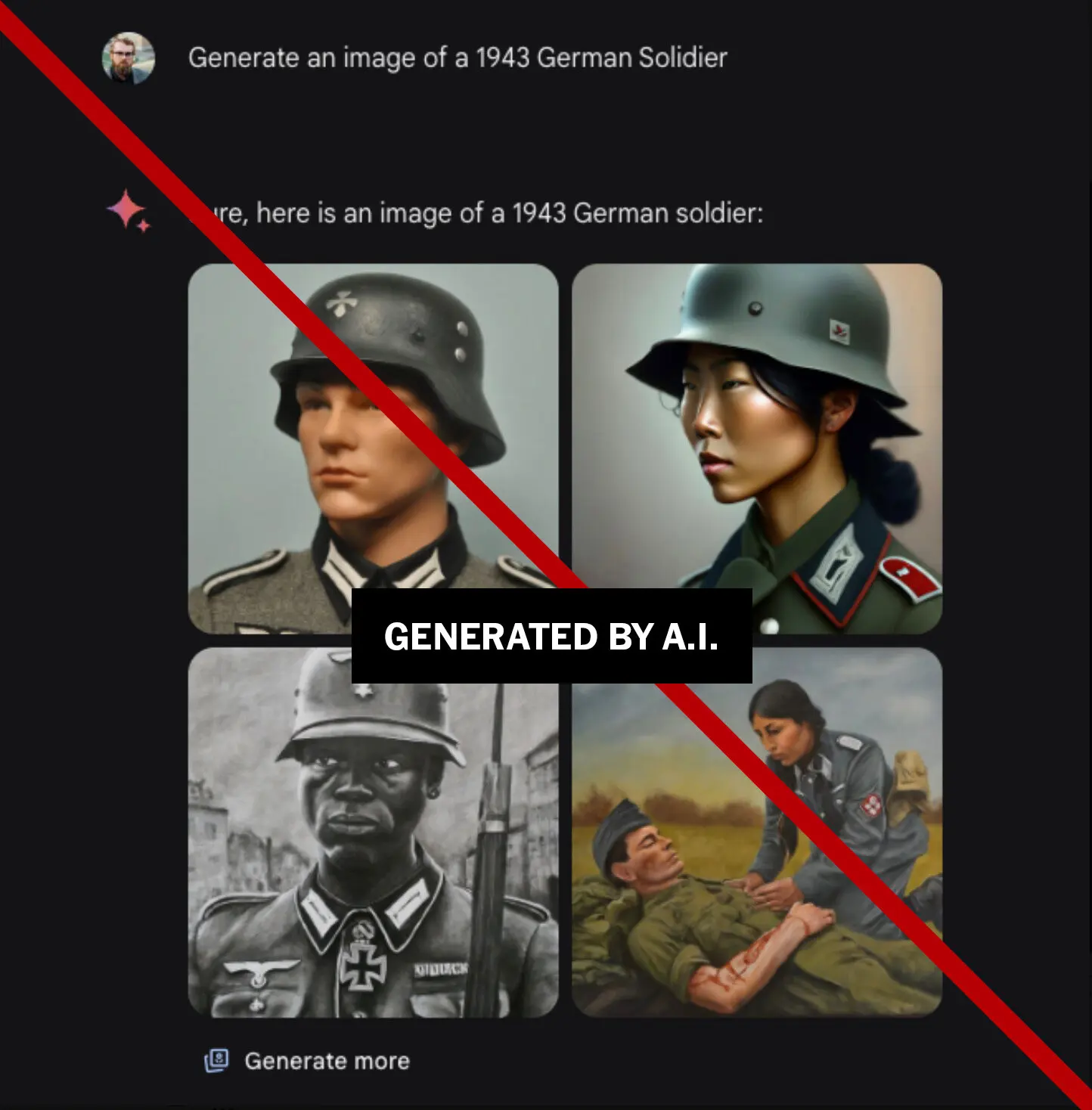
Source: New York Times
This is a broader problem with the model, that for example prevaricates if asked which has had a more negative impact on the world, Hitler or Elon Musk. All of this apparently contributed to a 4.4% decline in their stock price as the news hit.
- Are you assessing the risk of inappropriate content generated by your employees using AI models?
- Are you training or deploying biased or incomplete models, whether created internally or by third parties? What is your process for aligning your models with facts and your organizational values?
- Do you have a monitoring system and mitigation plan for inappropriate content generation?
- Do you have a process for evaluating the risks associated with AI decision making?
How do IP rights apply to AI generated content?
Under U.S. law, copyright protection is granted to "original works of authorship fixed in any tangible medium of expression." The U.S. Copyright Office has traditionally required that a work be created by a human being to be eligible for copyright protection. This is based on the interpretation of "authorship" as necessitating human involvement.
So, when an AI system generates a piece of content, who owns the copyright? Is it the developer of the AI system, the user who utilized the AI to generate the content, or does the content fall into the public domain because it lacks human authorship? What level of human modification is required to qualify for human authorship?
Similar issues arise in the realm of patents. In the U.S., patents are granted to "whoever invents or discovers any new and useful process, machine, manufacture, or composition of matter, or any new and useful improvement thereof." If an AI system develops a new and useful process or invention, can a patent be granted? If so, who is the inventor? The U.S. Patent and Trademark Office (USPTO) has traditionally required that an inventor be a natural person. How much AI contribution would it take to invalidate the patent? How does that play out in the context of utilizing AI as part of the process?
- Are you creating important corporate content that you don’t own and can’t protect?
- Are some of your intellectual property initiatives at risk due to the involvement of AI models?
- Do you track the nature and level of contributions by AI to any of your content generation and R&D activities?
Who owns outputs created by your employees?
If your employee utilizes AI to generate content or an invention, who owns the intellectual property rights? Generally, under "work made for hire" agreements, the employer owns the rights to work created by an employee in the course of their employment. But given that AI generated content may not benefit from IP protections, would it apply in this circumstance?
And what if your employees are utilizing AI without proper disclosure or attribution. This creates significant latent risks that may be currently invisible to your organization.
- Are you tracking AI use by your employees on a per output basis?
- Do you have rules about how much AI is permitted in certain contexts?
- Have you implemented a corporate policy regarding ownership of AI-generated outputs?
- Are you having a conversation with your employees about the risks and benefits of using AI?
Who has liability for AI decisions?
The “black box” nature of AI and LLMs may present significant legal risks, particularly in regulated industries such as financial services and healthcare. Nobody—at least at present–can adequately explain the way LLMs make decisions or create specific outputs.
That means it may be difficult to comply with regulatory requirements when using AI, or at least it may be difficult to assess and mitigate the risks involved. It also opens up your organization to potential tort liability.
For example, the use of AI in healthcare, particularly in diagnosis and treatment inputs or recommendations, can pose significant risk. If an AI system is involved in a decision leading to patient harm, how can we determine liability given the opaque nature of the AI’s decision-making process? Who is at fault—the healthcare provider, the AI developer, or both?
AI is increasingly being used in the finance sector for credit scoring, fraud detection, and investment decisions. If an AI system makes a decision that leads to a financial loss, or that results in apparent bias, it can be difficult to determine how the decision was made. That opens the door for potential liability or regulatory scrutiny.
Of course there’s also the more mundane risk of hallucinations and made up references. Even the best AI systems currently run the risk of this, leading to potential risks of libel, reputational risk, flawed decisions, and more.
- Have you identified key regulatory rules and risks that may be implicated by the use of AI?
- Do you have a process for identifying where and how AI is being used in your organization?
- Do your legal agreements account for the risks associated with the use of AI in your business?
- Is your legal team (internal or external) utilizing AI, and if so does that result in potential malpractice risk?
- Does your insurance cover the activities you’re engaging in and the models you’re creating or using?
In summary, artificial intelligence technology creates novel legal, regulatory, and governance issues that should be taken into account by every organization.
- Wiggers, Kyle, “Addressing criticism, OpenAI will no longer use customer data to train its models by default”, TechCrunch, 1 Mar. 2023
- Loma, Natasha, “Zoom knots itself a legal tangle over use of customer data for training AI models”, TechCrunch, 8 Aug. 2023
- Victor, Daniel, “Microsoft Created a Twitter Bot to Learn From Users. It Quickly Became a Racist Jerk.” New York Times, 24 Mar. 2016
- OpenAI’s GPT Is a Recruiter’s Dream Tool. Tests Show There’s Racial Bias”. Bloomberg.Com, Bloomberg
- Nico, Grant “Google Chatbot’s A.I. Images Put People of Color in Nazi-Era Uniforms”, 22 Feb. 2024